In physical cosmology, dark energy is a hypothetical exotic form of energy that permeates all of space and tends to increase the rate of expansion of the universe.[1] Dark energy is the most popular way to explain recent observations that the universe appears to be expanding at an accelerating rate. In the standard model of cosmology, dark energy currently accounts for 74% of the total mass-energy of the universe. Two proposed forms for dark energy are the cosmological constant, a constant energy density filling space homogeneously,[2] and scalar fields such as quintessence or moduli, dynamic quantities whose energy density can vary in time and space. Contributions from scalar fields that are constant in space are usually also included in the cosmological constant. The cosmological constant is physically equivalent to vacuum energy. Scalar fields which do change in space can be difficult to distinguish from a cosmological constant because the change may be extremely slow.
High-precision measurements of the expansion of the universe are required to understand how the expansion rate changes over time. In general relativity, the evolution of the expansion rate is parameterized by the cosmological equation of state. Measuring the equation of state of dark energy is one of the biggest efforts in observational cosmology today.
Adding the cosmological constant to cosmology's standard FLRW metric leads to the Lambda-CDM model, which has been referred to as the "standard model" of cosmology because of its precise agreement with observations. Dark energy has been used as a crucial ingredient in a recent attempt[3] to formulate a cyclic model for the universe.
Evidence for dark energy
Supernovae
In 1998, observations of type 1a supernovae ("one-A") by the Supernova Cosmology Project at the Lawrence Berkeley National Laboratory and the High-z Supernova Search Team suggested that the expansion of the universe is accelerating.[4][5] Since then, these observations have been corroborated by several independent sources. Measurements of the cosmic microwave background, gravitational lensing, and the large scale structure of the cosmos as well as improved measurements of supernovae have been consistent with the Lambda-CDM model.[6]
Supernovae are useful for cosmology because they are excellent standard candles across cosmological distances. They allow the expansion history of the Universe to be measured by looking at the relationship between the distance to an object and its redshift, which gives how fast it is receding from us. The relationship is roughly linear, according to Hubble's law. It is relatively easy to measure redshift, but finding the distance to an object is more difficult. Usually, astronomers use standard candles: objects for which the intrinsic brightness, the absolute magnitude, is known. This allows the object's distance to be measured from its actually observed brightness, or apparent magnitude. Type Ia supernovae are the best-known standard candles across cosmological distances because of their extreme, and extremely consistent, brightness.
Cosmic Microwave Background

Estimated distribution of dark matter and dark energy in the universe
The existence of dark energy, in whatever form, is needed to reconcile the measured geometry of space with the total amount of matter in the universe. Measurements of cosmic microwave background (CMB) anisotropies, most recently by the WMAP satellite, indicate that the universe is very close to flat. For the shape of the universe to be flat, the mass/energy density of the universe must be equal to a certain critical density. The total amount of matter in the universe (including baryons and dark matter), as measured by the CMB, accounts for only about 30% of the critical density. This implies the existence of an additional form of energy to account for the remaining 70%.[6] The most recent WMAP observations are consistent with a universe made up of 74% dark energy, 22% dark matter, and 4% ordinary matter. (Note: There is a slight discrepancy in the 'pie chart'.)
Large-Scale Structure
The theory of large scale structure, which governs the formation of structure in the universe (stars, quasars, galaxies and galaxy clusters), also suggests that the density of matter in the universe is only 30% of the critical density.
Late-time Integrated Sachs-Wolfe Effect
Accelerated cosmic expansion causes gravitational potential wells and hills to flatten as photons pass through them, producing cold spots and hot spots on the CMB aligned with vast supervoids and superclusters. This so-called late-time Integrated Sachs-Wolfe effect (ISW) is a direct signal of dark energy in a flat universe,[7] and has recently been detected at high significance by Ho et al.[8] and Giannantonio et al.[9] In May 2008, Granett, Neyrinck & Szapudi found arguably the clearest evidence yet for the ISW effect,[10] imaging the average imprint of superclusters and supervoids on the CMB.
Nature of dark energy
The exact nature of this dark energy is a matter of speculation. It is known to be very homogeneous, not very dense and is not known to interact through any of the fundamental forces other than gravity. Since it is not very dense?roughly 10?29 grams per cubic centimeter?it is hard to imagine experiments to detect it in the laboratory. Dark energy can only have such a profound impact on the universe, making up 74% of all energy, because it uniformly fills otherwise empty space. The two leading models are quintessence and the cosmological constant. Both models include the common characteristic that dark energy must have negative pressure.
Negative Pressure
Independently from its actual nature, dark energy would need to have a strong negative pressure in order to explain the observed acceleration in the expansion rate of the universe.
According to General Relativity, the pressure within a substance contributes to its gravitational attraction for other things just as its mass density does. This happens because the physical quantity that causes matter to generate gravitational effects is the Stress-energy tensor, which contains both the energy (or matter) density of a substance and its pressure and viscosity.
In the Friedmann-Lemaitre-Robertson-Walker metric, it can be shown that a strong constant negative pressure in all the universe causes an acceleration in universe expansion if the universe is already expanding, or a deceleration in universe contraction if the universe is already contracting. More exactly, the second derivative of the universe scale factor, 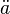 , is positive if the equation of state of the universe is such that w < ? 1 / 3.
, is positive if the equation of state of the universe is such that w < ? 1 / 3.
This accelerating expansion effect is sometimes labeled "gravitational repulsion", which is a colorful but possibly confusing expression. In fact a negative pressure does not influence the gravitational interaction between masses - which remains attractive - but rather alters the overall evolution of the universe at the cosmological scale, typically resulting in the accelerating expansion of the universe despite the attraction among the masses present in the universe.
Cosmological constant
-
-
The simplest explanation for dark energy is that it is simply the "cost of having space": that is, a volume of space has some intrinsic, fundamental energy. This is the cosmological constant, sometimes called Lambda (hence Lambda-CDM model) after the Greek letter Λ, the symbol used to mathematically represent this quantity. Since energy and mass are related by E = mc2, Einstein's theory of general relativity predicts that it will have a gravitational effect. It is sometimes called a vacuum energy because it is the energy density of empty vacuum. In fact, most theories of particle physics predict vacuum fluctuations that would give the vacuum exactly this sort of energy. This is related to the Casimir Effect, in which there is a small suction into regions where virtual particles are geometrically inhibited from forming (e.g. between plates with tiny separation). The cosmological constant is estimated by cosmologists to be on the order of 10?29g/cm3, or about 10?120 in reduced Planck units. Particle physics predicts a natural value of 1 in reduced Planck units, quite a bit off.
The cosmological constant has negative pressure equal to its energy density and so causes the expansion of the universe to accelerate. The reason why a cosmological constant has negative pressure can be seen from classical thermodynamics; Energy must be lost from inside a container to do work on the container. A change in volume dV requires work done equal to a change of energy ?p dV, where p is the pressure. But the amount of energy in a box of vacuum energy actually increases when the volume increases (dV is positive), because the energy is equal to ρV, where ρ (rho) is the energy density of the cosmological constant. Therefore, p is negative and, in fact, p = ?ρ.
A major outstanding problem is that most quantum field theories predict a huge cosmological constant from the energy of the quantum vacuum, more than 100 orders of magnitude too large.[11] This would need to be cancelled almost, but not exactly, by an equally large term of the opposite sign. Some supersymmetric theories require a cosmological constant that is exactly zero, which does not help. The present scientific consensus amounts to extrapolating the empirical evidence where it is relevant to predictions, and fine-tuning theories until a more elegant solution is found. Philosophically, our most elegant solution may be to say that if things were different, we would not be here to observe anything ? the anthropic principle.[12] Technically, this amounts to checking theories against macroscopic observations. Unfortunately, as the known error-margin in the constant predicts the fate of the universe more than its present state, many such "deeper" questions remain unknown.
Another problem arises with inclusion of the cosmic constant in the standard model: i.e., the appearance of solutions with regions of discontinuities (see classification of discontinuities for three examples) at low matter density.[13] Discontinuity also affects the past sign of the pressure assigned to the cosmic constant, changing from the current negative pressure to attractive, as one looks back towards the early Universe. A systematic, model-independent evaluation of the supernovae data supporting inclusion of the cosmic constant in the standard model indicates these data suffer systematic error. The supernovae data are not overwhelming evidence for an accelerating Universe expansion which may be simply gliding.[14] A numerical evaluation of WMAP and supernovae data for evidence that our local group exists in a local void with poor matter density compared to other locations, uncovered possible conflict in the analysis used to support the cosmic constant.[15] These findings should be considered shortcomings of the standard model, but only when a term for vacuum energy is included.
In spite of its problems, the cosmological constant is in many respects the most economical solution to the problem of cosmic acceleration. One number successfully explains a multitude of observations. Thus, the current standard model of cosmology, the Lambda-CDM model, includes the cosmological constant as an essential feature.
Quintessence
-
In quintessence models of dark energy, the observed acceleration of the scale factor is caused by the potential energy of a dynamical field, referred to as quintessence field. Quintessence differs from the cosmological constant in that it can vary in space and time. In order for it not to clump and form structure like matter, the field must be very light so that it has a large Compton wavelength.
No evidence of quintessence is yet available, but it has not been ruled out either. It generally predicts a slightly slower acceleration of the expansion of the universe than the cosmological constant. Some scientists think that the best evidence for quintessence would come from violations of Einstein's equivalence principle and variation of the fundamental constants in space or time. Scalar fields are predicted by the standard model and string theory, but an analogous problem to the cosmological constant problem (or the problem of constructing models of cosmic inflation) occurs: renormalization theory predicts that scalar fields should acquire large masses.
The cosmic coincidence problem asks why the cosmic acceleration began when it did. If cosmic acceleration began earlier in the universe, structures such as galaxies would never have had time to form and life, at least as we know it, would never have had a chance to exist. Proponents of the anthropic principle view this as support for their arguments. However, many models of quintessence have a so-called tracker behavior, which solves this problem. In these models, the quintessence field has a density which closely tracks (but is less than) the radiation density until matter-radiation equality, which triggers quintessence to start behaving as dark energy, eventually dominating the universe. This naturally sets the low energy scale of the dark energy.
Some special cases of quintessence are phantom energy, in which the energy density of quintessence actually increases with time, and k-essence (short for kinetic quintessence) which has a non-standard form of kinetic energy. They can have unusual properties: phantom energy, for example, can cause a Big Rip.
Alternative ideas
Some theorists think that dark energy and cosmic acceleration are a failure of general relativity on very large scales, larger than superclusters. It is a tremendous extrapolation to think that our law of gravity, which works so well in the solar system, should work without correction on the scale of the universe. Most attempts at modifying general relativity, however, have turned out to be either equivalent to theories of quintessence, or inconsistent with observations. It is of interest to note that if the equation for gravity were to approach r instead of r2 at large, intergalactic distances, then the acceleration of the expansion of the universe becomes a mathematical artifact,[clarify] negating the need for the existence of Dark Energy.
Alternative ideas for dark energy have come from string theory, brane cosmology and the holographic principle, but have not yet proved as compelling as quintessence and the cosmological constant. On string theory, an article in the journal Nature described:
String theories, popular with many particle physicists, make it possible, even desirable, to think that the observable universe is just one of 10500 universes in a grander multiverse, says [Leonard Susskind, a cosmologist at Stanford University in California]. The vacuum energy will have different values in different universes, and in many or most it might indeed be vast. But it must be small in ours because it is only in such a universe that observers such as ourselves can evolve.[11]
Paul Steinhardt in the same article criticizes string theory's explanation of dark energy stating "...Anthropics and randomness don't explain anything... I am disappointed with what most theorists are willing to accept".[11]
In a rather radical departure, an article in the open access journal, Entropy, by Professor Paul Gough, put forward the suggestion that information energy must make a significant contribution to dark energy and that this can be shown by referencing the equation of the state of information in the universe. [16]
Yet another, "radically conservative" class of proposals aims to explain the observational data by a more refined use of established theories rather than through the introduction of dark energy, focusing, for example, on the gravitational effects of density inhomogeneities [17][18] or on consequences of electroweak symmetry breaking in the early universe.
Implications for the fate of the universe
Cosmologists estimate that the acceleration began roughly 5 billion years ago. Before that, it is thought that the expansion was decelerating, due to the attractive influence of dark matter and baryons. The density of dark matter in an expanding universe decreases more quickly than dark energy, and eventually the dark energy dominates. Specifically, when the volume of the universe doubles, the density of dark matter is halved but the density of dark energy is nearly unchanged (it is exactly constant in the case of a cosmological constant).
If the acceleration continues indefinitely, the ultimate result will be that galaxies outside the local supercluster will move beyond the cosmic horizon: they will no longer be visible, because their line-of-sight velocity becomes greater than the speed of light. This is not a violation of special relativity, and the effect cannot be used to send a signal between them. (Actually there is no way to even define "relative speed" in a curved spacetime. Relative speed and velocity can only be meaningfully defined in flat spacetime or in sufficiently small (infinitesimal) regions of curved spacetime). Rather, it prevents any communication between them and the objects pass out of contact. The Earth, the Milky Way and the Virgo supercluster, however, would remain virtually undisturbed while the rest of the universe recedes. In this scenario, the local supercluster would ultimately suffer heat death, just as was thought for the flat, matter-dominated universe, before measurements of cosmic acceleration.
There are some very speculative ideas about the future of the universe. One suggests that phantom energy causes divergent expansion, which would imply that the effective force of dark energy continues growing until it dominates all other forces in the universe. Under this scenario, dark energy would ultimately tear apart all gravitationally bound structures, including galaxies and solar systems, and eventually overcome the electrical and nuclear forces to tear apart atoms themselves, ending the universe in a "Big Rip". On the other hand, dark energy might dissipate with time, or even become attractive. Such uncertainties leave open the possibility that gravity might yet rule the day and lead to a universe that contracts in on itself in a "Big Crunch". Some scenarios, such as the cyclic model suggest this could be the case. While these ideas are not supported by observations, they are not ruled out. Measurements of acceleration are crucial to determining the ultimate fate of the universe in big bang theory.
History
The cosmological constant was first proposed by Einstein as a mechanism to obtain a stable solution of the gravitational field equation that would lead to a static universe, effectively using dark energy to balance gravity. Not only was the mechanism an inelegant example of fine-tuning, it was soon realized that Einstein's static universe would actually be unstable because local inhomogeneities would ultimately lead to either the runaway expansion or contraction of the universe. The equilibrium is unstable: if the universe expands slightly, then the expansion releases vacuum energy, which causes yet more expansion. Likewise, a universe which contracts slightly will continue contracting. These sorts of disturbances are inevitable, due to the uneven distribution of matter throughout the universe. More importantly, observations made by Edwin Hubble showed that the universe appears to be expanding and not static at all. Einstein famously referred to his failure to predict the idea of a dynamic universe, in contrast to a static universe, as his greatest blunder. Following this realization, the cosmological constant was largely ignored as a historical curiosity.
Alan Guth proposed in the 1970s that a negative pressure field, similar in concept to dark energy, could drive cosmic inflation in the very early universe. Inflation postulates that some repulsive force, qualitatively similar to dark energy, resulted in an enormous and exponential expansion of the universe slightly after the Big Bang. Such expansion is an essential feature of most current models of the Big Bang. However, inflation must have occurred at a much higher energy density than the dark energy we observe today and is thought to have completely ended when the universe was just a fraction of a second old. It is unclear what relation, if any, exists between dark energy and inflation. Even after inflationary models became accepted, the cosmological constant was thought to be irrelevant to the current universe.
The term "dark energy" was coined by Michael Turner in 1998.[19] By that time, the missing mass problem of big bang nucleosynthesis and large scale structure was established, and some cosmologists had started to theorize that there was an additional component to our universe. The first direct evidence for dark energy came from supernova observations of accelerated expansion, in Riess et al[5] and later confirmed in Perlmutter et al..[4] This resulted in the Lambda-CDM model, which as of 2006 is consistent with a series of increasingly rigorous cosmological observations, the latest being the 2005 Supernova Legacy Survey. First results from the SNLS reveal that the average behavior (i.e., equation of state) of dark energy behaves like Einstein's cosmological constant to a precision of 10 per cent.[20] Recent results from the Hubble Space Telescope Higher-Z Team indicate that dark energy has been present for at least 9 billion years and during the period preceding cosmic acceleration.