blogeyeの実装に学ぶ、Amazon EC2/S3でのHadoop活用術:CodeZine
blogeyeとは
「blogeye」(ブログアイ)は日本語のブログをクロール、リアルタイムに分析して、流行語と思われるものを推定し、ランキング形式で提供しているサイトです。特徴として、ブログサイトごとにその著者の性別・年齢・居住都道府県を推定しているため、流行語を著者属性ごとに推定したり、ユーザーが入力したキーワードや流行語を特によく使っている著者属性を表示したりすることができます。
blogeye
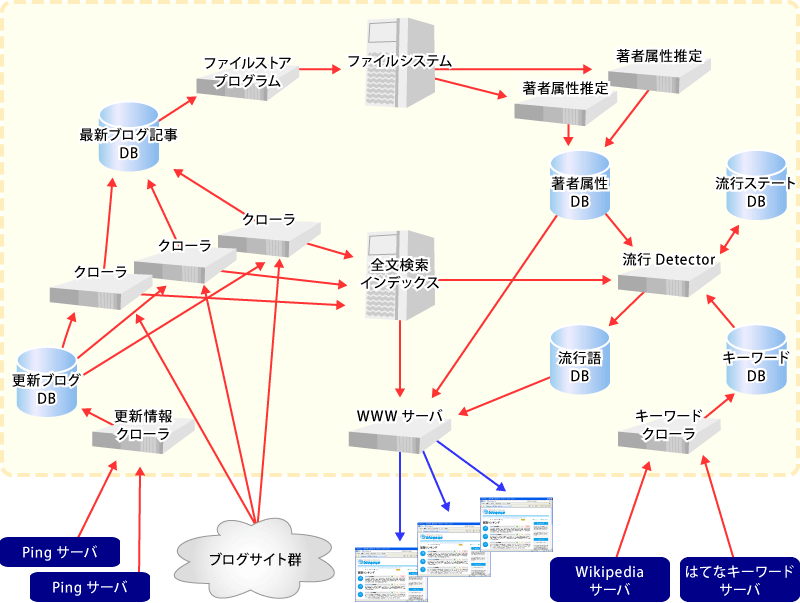
blogeyeの構成
blogeye全体の構成は下図のようになっています。
ブログのクローリング
まず、更新情報のクローラ(図の左下)がPingサーバーからブログの更新情報を取得し、更新ブログデータベース(MySQL)に格納しています。この更新ブログデータベースの情報を元に、クローラがブログサイトにアクセスし、記事を取得します。このクローリング処理はHadoopで分散処理されます。
ブログ記事データベースにまだ含まれていない記事であればそれをブログ記事データベース(MySQL)に挿入すると共に、一時的な全文検索インデックス(Senna)に登録します。ブログ記事データベースのデータは1日に1回、ファイルシステム(S3)に書き込み、記事データベースからは削除します。
著者属性の推定
著者属性推定プログラム(図の右上)は、ファイルシステム(S3)から過去にクロールしたすべての記事データを読み出し、日付ごとに管理されている記事をブログサイトごとにまとめなおして、各々のサイトについて著者属性を推定し、結果を著者属性データベースに格納します。
流行度スコアの算出
キーワードクローラ(図の右下)はWikipediaの更新情報などからキーワードリストを取得し、キーワードデータベースに登録します。キーワードデータベースに登録されたデータは全文検索インデックスと著者属性データベースと共に流行Detector(流行度スコア計算のプログラム)で処理され、結果の流行度スコアが流行語データベースに登録されます。
流行語のランキングを表示
ユーザー(図の中央下部)がブラウザを通じてクエリを送ると、Webサーバが流行語データベースや全文検索インデックスの内容を参照してページを生成し、ブラウザに返送します。
Amazon EC2/S3の利用
blogeyeでは1日に50万~70万のブログ記事をクロールしており、システム内部には2億ページ強の記事を保管しています。blogeyeで行っている並列化が必要な処理は、大きく分けて2つあります。
1つはブログの更新情報を提供しているサービスであるpingサーバからのデータ取得や、ブログ記事の取得などの「クロール処理」です。2つ目は、「著者属性を推定する処理」です。クロールのように常に行う処理ではないですが、クロールしたすべての記事をサイトごとにまとめ直し、各サイトの著者属性を推定する大きな処理です。この2つの処理を行うため、Amazon EC2上に
Hadoopクラスタを構成しました。HadoopとAmazon EC2
HadoopとEC2はとても相性がよく、EC2の特徴である「必要なときに必要なだけ計算機リソースをレンタルできる」という性質を
Hadoopクラスタにも継承できます。
Hadoopクラスタを拡大したい時にはHadoopの開発者コミュニティが用意してくれているAMI(Amazon Machine Image)を自分で起動します。スレーブとして動作させるためのパラメータやマスターのアドレスを与えてこのAMIから起動すれば自動的にマスターに接続し、クラスタのスレーブとして認識されます。逆にクラスタを縮小したい場合には、いくつかのスレーブのインスタンスを単に終了します。終了させたマシンで実行されていたタスクは失敗しますが、Hadoopのマスターはこの失敗を検出して同じタスクを他のマシンに割り当て直すことにより、ジョブを問題なく継続してくれます。HadoopとAmazon S3
また、EC2と共に利用できるS3もHadoopから利用するためのライブラリが提供されており、Hadoopから利用するファイルシステム(HDFS)をS3上に構築することができます。これを利用することで、クラスタ全体を再起動するような際にも、データを失う心配がなくなります。blogeyeでは、ブログデータやHadoopから読み出すデータの多くを HDFSのラッパを通してS3上に保管しています。

0 件のコメント:
コメントを投稿