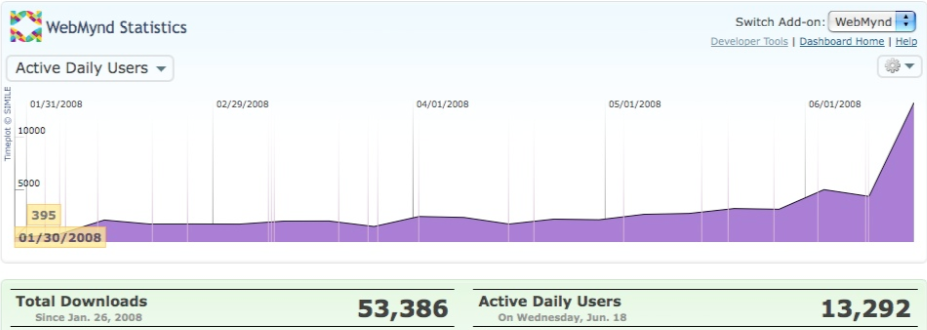
Like any application developed for a platform, the success of a Firefox Add-on is closely tied to the popularity and distribution you get from the underlying delivery mechanism. So, when we honed down the WebMynd feature set, improving the product enough to get on Mozilla’s Recommended List, we were delighted by our increasing user numbers. A couple of weeks later, Firefox 3 was released, and we got a usage graph like this:
With a product like WebMynd, where part of the service we provide is to save and index a person’s web history, this sort of explosive expansion brings with it some growing pains. Performance was a constant battle with us, even with the relatively low user numbers of the first few months. This was due mainly to some poor technology choices; thankfully, the underlying architecture we chose from the start has proven to be sound.
I would not say that we have completely solved the difficult problem in front of us - we are still not content with the responsiveness of our service, and we’re open about the brown-outs we still sometimes experience - but we have made huge progress and learned some invaluable lessons over the last few months.
What follows is a high level overview of some of the conclusions we’ve arrived at today, best practices that work for us and some things to avoid. In later weeks, I plan to follow up with deeper dives into certain parts of our infrastructure as and when I get a chance!
Scaling is all about removing bottlenecks
This sounds obvious, but should strongly influence all your technology and architecture decisions.
Being able to remove bottlenecks means you need to be able to swap out discrete parts which aren’t performing well enough, and swap in bigger, faster, better parts which will perform as required. This will move the bottleneck somewhere else, at which point you need to swap out discrete parts which aren’t performing well enough, and swap in bigger, faster, better parts… well you get the idea. This cycle can be repeated ad infinitum until you’ve optimised the heck out of everything and you’re just throwing machines at the problem.
At WebMynd, for our search backend, we’ve done this four or five times already in the five months we’ve been alive, and I think I still have some iterations left in me. Importantly, I wouldn’t say that any of these iterations were a mistake. In a parallel to the Y Combinator ethos of launching a product early, scaling should be an iterative process with as close a feedback loop as possible. Premature optimisation of any part of the service is a waste of time and is often harmful.
Scaling relies on having discrete pieces with clean interfaces, which can be iteratively improved.
Horizontal is better than vertical
One of the reasons Google triumphed in the search engine wars was that their core technology was designed from the ground up to scale horizontally across cheap hardware. Compare this with their competitors’ approach, which was in general to scale vertically - using larger and larger monolithic machines glued together organically. Other search engines relied on improving hardware to cope with demand, but when the growth of the internet outstripped available hardware, they had nowhere to go. Google was using inferior pieces of hardware, but had an architecture and infrastructure allowing for cheap and virtually limitless scaling.
Google’s key breakthroughs were the Google File System and MapReduce, which together allow them to horizontally partition the problem of indexing the web. If you can architect your product in such a way as to allow for similar partitioning, scaling will be all the more easy. It’s interesting to note that some of the current trends of Web2.0 products are extremely hard to horizontally partition, due to the hyper-connectedness of the user graph (witness Twitter).
The problem WebMynd is tackling is embarrassingly partitionable. Users have their individual slice of web history, and these slices can be moved around the available hardware at will. New users equals new servers.
Hardware is the lowest common denominator
By running your application on virtual machines using EC2, you are viewing the hardware you’re running on as a commodity which can be swapped in and out at the click of a button. This is an useful mental model to have, where the actual machine images you’re running on are just another component in your architecture which can be scaled up or down as demand requires. Obviously, if you’re planning on scaling horizontally, you need to be building on a substrate which has low marginal cost for creating and destroying hardware - marginal cost in terms of time, effort and capex.
A real example
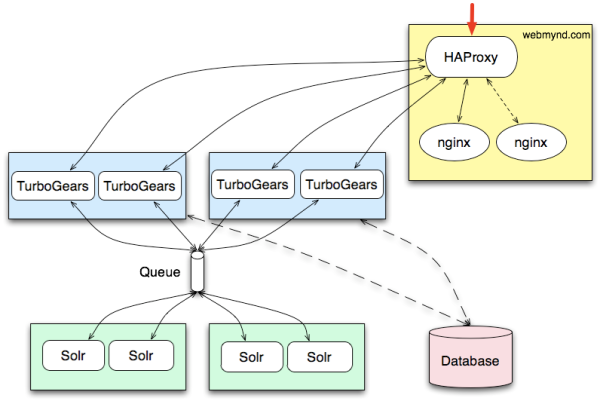
To put the above assertions into context, I’ll use WebMynd’s current architecture:
The rectangles represent EC2 instances. Their colour represents their function. The red arrow in the top right represents incoming traffic. Other arrows represent connectedness and flows of information.
This is a simplified example, but here’s what the pieces do in general terms:
- All traffic is currently load balanced by a single HAProxy instance
- All static content is served from a single nginx instance (with a hot failover ready)
- Sessions are distributed fairly across lots of TurboGears application servers, on several machines
- The database is a remote MySQL instance
- Search engine updates are handled asynchronously through a queue
- Search engine queries are handled synchronously over a direct TurboGears / Solr connection (not shown)
One shouldn’t be timid in trying new things to find the best solution; almost all of these parts have been iterated on like crazy. For example, we’ve used Apache with mod_python, Apache with mod_proxy, Apache with mod_wsgi. We’ve used TurboLucene, looked very hard at Xapian, various configurations of Solr.
For the queue, I’ve written my own queuing middleware, I’ve used ActiveMQ running on an EC2 instance and I’m now in the process of moving to Amazon’s SQS. We chose to use SQS as although ActiveMQ is free as in beer and speech, it has an ongoing operations cost in terms of time, which is one thing you’re always short of during hyper-growth.
The two parts which are growing the fastest are the web tier (the TurboGears servers) and the search tier (the Solr servers). However, as we can iterate on our implementations and rapidly horizontally scale on both of those parts, that growth has been containable, if not completely pain free.
Amazon’s Web Services give growing companies the ideal building blocks to scale and keep up with demand. By iteratively improving the independent components in our architecture, we have grown to meet the substantial challenge of providing the WebMynd service to our users.

2008年10月19日日曜日
Scaling on EC2 « WebMynd Blog
Scaling on EC2 ≪ WebMynd Blog
登録:
コメントの投稿 (Atom)
ブログ アーカイブ
-
▼
2008
(24)
-
▼
10月
(23)
- Kill the data loss monster once and for all
- 緊急提案! 急激な円高にはネット外貨普通預金がオススメ | ライフ | マイコミジャーナル
- [science][physics]ダークエネルギー
- Dark energy - Wikipedia, the free encyclopedia
- [dev][sbm]Kikker の学習の仕組みと Rocchio アルゴリズム - naoyaのは...
- [dev]blogeyeの実装に学ぶ、Amazon EC2/S3でのHadoop活用術
- Python 3.0 Interview
- Brian "Krow" Aker's Idle Thoughts - Assumptions, D...
- いま開いているページを簡単に携帯で読むためのブックマークレット(はてなMobileGateway+ポ...
- Opera 9.6 Launches, Now Includes Magazine-Style RS...
- Wall Street Staggers
- BSDCan 2008: ZFS Internals | KernelTrap
- Twitter, SearchMonkey, and Caching (Yahoo! Develop...
- BOSS ? The Next Step in our Open Search Ecosystem ...
- Preparing For EC2 Persistent Storage
- PythonSpeed - PythonInfo Wiki
- There's a bright cloud on the horizon ... and it w...
- Scaling on EC2 « WebMynd Blog
- Is the Cloud Right for You? Ask Yourself These 5 Q...
- Why Social Software Makes for Poor Recommendations...
- Why Corporates Hate Perl
- Credit doors are closing - International Herald Tr...
- Crisis And Bailout - by Michele Boldrin and David ...
-
▼
10月
(23)
自己紹介
- rawwell
- twitter: http://twitter.com/rawwell
That’s really cool. I appreciate the effort you took to explain your architecture, it helps others see how scaling with EC2 can work in practice. Thanks.
You guys have a chance to try Sphinx for full-text indexing? It’s C++, open source, and wicked fast. Depending on what features you need, it might be a good idea to try it out. Here’s one of the benchmarks I’ve seen for Solr versus Sphinx:
http://blog.evanweaver.com/articles/2008/03/17/rails-search-benchmarks/
This is what we use for our Firefox extension, bug.gd, which we’ve been growing into the world’s largest database/search engine for error messages:
https://addons.mozilla.org/en-US/firefox/addon/6138
The reindexing time is simply amazing with Sphinx. It allows us to get user searches into the index very quickly? when we first launched we could have been doing a quick reindex on almost every query because it was so very fast.
Thanks for sharing this? very cool to see a lot of decisions for another web app of ours being echoed in your choices.
@Matthew: we haven’t looked at Sphinx in any detail, although I’d be open to switching if benchmarking our load showed clear advantages.
Obviously, there is a pretty big switching cost in moving data from one search engine to another, or a large ongoing cost in supporting two engines if you ran both in parallel, so we’d need compelling reason.
Our main challenge right now is ensuring freshness of data, which is one thing Sphinx seems to emphasise, so perhaps I should pencil in an iteration
James, great stuff, thanks for sharing the backend architecture - it’s always interesting to see how these things are built. Out of curiosity, are you guys using Solr replication at all? It looks like you’re updating multiple Solr instances at once - do you have logic to guarantee data consistency? Why not use the built-in replication model in Solr?
@Ilya I’ll leave the details for another post, but yes, we are using Solr’s replication facility: in fact I’d say it’s a key enabler for us to even start tackling the problem.
For our particular service, delaying, or even losing, some documents is not as disastrous as it would be in other domains, so we tend to opt for lighter weight checking and alerting rather than up-front data consistency logic.
excellent read.
you mention that the mysql instance is remote ? what happens when the bottleneck moves to the connection between EC2 and the mysql instance? this is probably inevitable at _some_ point, though there are a a LOT of things you can do to delay the inevitable for a long time (caching query results, queuing inserts/updates and doing them in batches, etc).
just curious.
- jonathan.
@jonathan absolutely - to assume that the bottleneck will never move to component X virtually guarantees that component X will saturate with 24 hours.
Our plan for MySQL is firstly to scale vertically, then horizontally. The reason we’ve chosen not to immediately scale horizontally is that we can still easily contain our workload on not particulary expensive hardware. There’s no economic or technical driver for us to put the effort in now to scale horizontally.
When that argument no longer holds, we could move to a master-slave setup, but as the database is just as embarrassingly partitionable as the search engine, we would probably just move to partition the database by user id.
Thanks for the real world stats, breakdowns, and architecture overview Amir, they are really useful!
Sorry James, thought amir wrote the article! Thanks James
I came to recommend Sphinx as well. Sphinx worked great as a search index for us, but was also useful for pulling aggregate statistics off of the search queries as well (queries that would be GROUP BY in MySQL). In-memory updates were also very useful for us, since we didn’t want to wait for an index to rebuild to reflect changes.
Thank you for taking the time to create that post! Very informative! I wish our tables were ” embarrassingly partitionable.”
I have a quick question: What is the technology chain between HAProxy and Turbo Gears? the TG built-in webserver? WSGI? Apache with mod_python? etc. I am really excited to start my next project using Python, but I’m finding it difficult to discover best practices for connecting everything together in a stable, manageable way.
Thanks in advance!
Scott
@scott Hi, yes that linkage from frontend to app server was definitely one we spent a lot of time experimenting with.
The current best setup we have is to run several standalone TurboGears instances, with the built-in CherryPy webserver, directly behind HAProxy.
In that scenario, running TG behind mod_python, mod_proxy or whatever else just isn’t necessary (and we found it really hurt performance). I really like the look of some of WSGI’s features, but we found support for it to be slightly flaky in the TG 1.x branch (can’t wait to try TG 2!)
Thanks James. Much appreciated!
James
Very intuitive and informative post. I was curious if you guys contemplated using Amazon’s SimpleDB as your database. I know it does not have all the bells and whistles of a traditional RDBMS , but given the reliability and scalability don’t you think it is worthwhile to give SimpleDB a shot.
@Karthik Yes, we did consider SimpleDB; the pricing and scaling characteristics is a convincing case for some situations. However, for us, we really felt like we needed full relational capabilities.
When you’re dealing with innately relational schemas, to use flat databases like SimpleDB and BigTable you need to denormalise your data to match the capabilities of the database. If an RDBMS can scale to match your needs (and in our case it can, easily), then it would be premature optimisation to trade in simplicity and functionality for scalability which might never be used.
@Mathew That benchmark doesn’t really give a very clear picture. It looks like it’s done with a very naieve Solr setup. Solr can gain a *lot* with a bit of configuration and playing around with much resource you let it use.