http://d.hatena.ne.jp/morchin/20081031#p1multiprocessingを使用しない場合は約27秒かかり、使用した場合は約14秒だった。タスクマネージャを見ていると、使用しない場合はCPUの使用率が50%~60%くらいだったが、使用した場合はCPUの使用率がほぼ100%だった。
multiprocessingを使用しても所詮はPythonなので遅い。Cythonなどを使用してC言語の方でマルチコアに対応できる必要があると思うが、どうすれば良いのだろう?Cythonが生成したCコードをIntel C++ Compilerとかでコンパイルすればできるのかな?
使用したことながったが、これでParallel Pythonは不要になると思う。
2008年11月4日火曜日
multiprocessingの時間計測
2008-10-31 - プログラミング日記
2008年10月30日木曜日
Kill the data loss monster once and for all
Kill the data loss monster once and for all | Tech Broiler | ZDNet.com
On the personal computing side, I can’t tell you how many times this year I’ve been called by a friend or family member to help fix a computer that has “crashed” or is unrecoverable. My first question is the obvious one - “So, how do you handle your backups?” I frequently get blank stares as a response, and that’s when I know we’re in big trouble.
If your primary storage medium really is unrecoverable - in other words, if you can’t get access to the data via something like System Rescue CD or successfully mount the drive on another computer to retrieve your files, you need to have some sort of backup mechanism where you can either restore your critical data to a newly rebuilt OS or do an image-based restore. Much of how this is accomplished depends on what we in the Business Continuity and Recovery Services business call your RTO and your RPO - or your Recovery Point Objective and Recovery Time Objective. For your average end user, the RPO is the most important consideration - you want to be able to recover your files and data at a point in time closest to when you incurred the actual data loss. Whether it takes you an hour or a day to get the data back (your RTO) for a home user or small business is probably unimportant. For an enterprise, that’s an entirely different matter - some companies require RTO’s of less than 4 hours, and some I’ve seen as high as 72 depending on the criticality of the system or tier. Very low RTOs and RPOs require some very sophisticated solutions such as SAN snapshotting, replication technologies and Disaster Recovery (DR) sites and protocols. But most end-users are usually happy just to get their data back, period, and don’t require anything nearly as infrastructure-intensive.
How can you as an end-user kill the data loss monster for good? Well, it’s as inexpensive in most cases as going out and buying a secondary USB hard disk for less than $100, attaching it to your personal computer, and installing a free piece of software such as Cucku Backup, which can be configured to automatically back up your system to that new device in less than 5 minutes. If you don’t want to keep a backup drive onsite, or want a secondary backup mechanism that would protect you in the event of a true disaster, such as a flood or a fire, you can look into solutions such as Carbonite which will automatically back up your critical data over the Internet for a small yearly fee depending on the amount of offline storage you buy. Iron Mountain, which is a high-end service that is usually reserved for Fortune 500 companies, also has an Internet-based backup solution for small businesses, but it’s a lot pricier.
As with any service, you need to weigh the maintenance fees against what a real failure would actually cost you, and what combination of services make the most sense and what data is more critical than others - obviously, your MP3 collection and your family photos from last Christmas probably aren’t as important as your Quicken/Quickbooks files or your Office documents, so you should be burning your non-critical or static data to cheap storage such as DVDs or a backup hard drive instead of using net-based backups which charge for storage and bandwidth by the gigabyte. Note to Google, Yahoo, Apple, Microsoft, IBM, HP and Amazon - here’s an area where you guys could really clean up and gain some serious customer loyalty — by providing affordable and easy to use Internet backup services.
In the event that you incur a complete hard disk failure, you’ll still need to re-install your OS and apps and your backup software package, no doubt a very time intensive process wrought with headaches, but you’ll get your important data back if you’ve been doing daily backups. To bring back your entire system with OS, apps, data and all with minimum stress, you might also want to look into image-based solutions such as Acronis or Symantec GHOST which can be combined with the aforementioned USB backup drives and traditional file-based backups to restore from incremental data loss. Linux users should definitely look at System Rescue CD for a great open source system imaging solution. As with any backup solution, image-based backups are only as good as how recent they were taken, so be sure to combine this with a file-based backup solution.
For those of you who want a completely transparent redundancy solution, you might want to consider putting in a second internal hard disk and configuring your system for RAID-1. RAID used to be for enterprises only, but every single consumer version of Windows has supported it out of the box since Windows XP, and it’s been in NT and “Enterprise” Windows desktops for ages. Simply install a second hard disk, partition it to be the exact size of your existing hard disk partitions, open up the Disk Manager in the Microsoft Management Console (MMC) and create a software RAID 1/Disk Mirror - no expensive RAID controller is needed, but your CPU will incur a little bit more overhead by mirroring the drive.
If your primary drive fails when you are using software mirroring, simply swap the cabling with your secondary drive and you are good to go - although it’s possible in some rare circumstances that you might destructively write or erase data on both drives simultaneously (I’ve seen this happen with things like database apps where no actual OS or hardware “crash” occurs but the application itself misbehaves causing a data loss) so you should always have a secondary backup/restore method handy. Linux also supports software-based drive mirroring, but the setup is a little more complicated and you’ll want to consult the ‘HOWTO’ guides on the Internet if you want to head down that route.
If you need higher disk performance and a no-brainer setup for Windows, Mac and Linux, you might want to look at a hardware-based solution from AMCC 3Ware or from Adaptec, both of which sell desktop caching SATA RAID controllers in the $200-$300 range depending on what features you need. Some motherboards on higher-end PCs also include RAID controller chipsets. With RAID controllers, you set up the mirroring in the controller BIOS and the RAID chipset does all the work - the host OS sees just one physical hard disk, even though you might have two or more (RAID-5) disks installed. When a drive fails, the controller does all the hard work of re-syncing the data when you put the replacement secondary hard disk back in.
Finally, let’s address another monster that a lot of users ignore - virus checking and anti-malware solutions. With so many inexpensive and well-designed programs on the market today, there’s no excuse for not having one installed or letting your subscription expire. On Windows I continue to be impressed with Symantec’s Norton Internet Security 2009 - it’s an excellent package and is far less resource intensive than previous versions for an all-in-one antivirus/antispyware/firewall solution. For a free antivirus I like Avast! Home Edition, and for anti-malware and routine system maintenance tools, IOBit’s Advanced Systemcare 3, CCleaner.com and Safer-Networking.org’s Spybot Search and Destroy should be on everyone’s download list.
With the inexpensive data resiliency and backup solutions available on the market today, you don’t need to be the victim of a bad horror movie.
Technorati Tags: backup, storage2008年10月29日水曜日
緊急提案! 急激な円高にはネット外貨普通預金がオススメ | ライフ | マイコミジャーナル
【レポート】緊急提案! 急激な円高にはネット外貨普通預金がオススメ | ライフ | マイコミジャーナル
為替市場が急激な円高に見舞われています。過去から外貨取引をしている人はピンチですが、今から始める、もしくは再開するという人にはチャンス到来ともいえるでしょう。
ただし、まだまだ為替の動きは乱高下が予想されますので、通常時の為替取引のセオリー「金利が高ければ、多少の円高は吸収できるので高金利の外債へ」とか「金利も高いし、すぐに引き出せるから外貨MMFで」といった考えは通用しません。何と言っても、100円だった米ドルが1日で94円になってしまう可能性だってあるのです。つまり単純に考えれば100万円預けたものが、1日で94万円に減ってしまうということ。つまり、1日でマイナス6%。金利 4%程度ではあっという間に吹っ飛ぶ可能性があるのです。
また外債もそうですが、外貨MMFも解約できるのは1日に1回ないし、2回。「今日は円高になりそうだから解約しよう」と思っても、朝100円だったものが午後には94円になっていたら、1日1回、終値で解約といった外貨MMFや外債はやはり、リスクが高いということになります。
もちろん、この点FX(外国為替証拠金取引)は、1日の間に自由に売買できますので、様々な技を駆使してピンチをチャンスに変えることができるかもしれません。しかし、このような荒い市場で、今から外貨取引デビューなどといっている人が突然FXに参入して、勝てるわけもありません。また、FXにはレバレッジという甘い罠があります。デビュー組がビギナーズ・ラックで1度大儲けすると、うれしくなって、ついつい10倍、20倍とレバレッジをあげてしまうものです。そう途端、激しい円高に見舞われ逃げ切れず、損失も10倍、20倍になってしまうこともありえます。
ここはもう少しおとなしめの外貨投資で様子が見るのがオススメといえます。
さて、それではどんな商品を利用して外貨投資を始めればいいのでしょう。それが、ネット銀行の外貨普通預金なのです。通常、銀行で外貨投資といえば外貨定期預金。普通預金は外貨定期をするための通り道程度の存在でした。ところが、最近の外貨普通預金はとにかくすごい! いつの間にか、超便利な外貨投資ツールに大変身しています。
そこで、もっともサービスが進んでいる住信SBIネット銀行の外貨普通預金の例でみてみましょう。取扱通貨は米ドル / ユーロ / 英ポンド / 豪ドル / NZドル / カナダドル / スイスフラン / 香港ドルの8通貨。一般的なFX取引にも匹敵する通貨のバリエーションがあります。しかも、為替手数料もFXには負けますが、以下の表のように割安。たとえば、米ドルの場合、通常の総合銀行の外貨定期だと1円、通常の証券会社の外貨MMFだと50銭のところ、住信SBIネット銀行なら20銭! その割安度がわかります。

また、取引時間も24時間365日可能(メンテナンス時間のぞく)。しかも、同行の場合、為替レートが市場に連動して、随時見直しされるのです。つまり、急激な円高がきたら、即座にその場の為替レートで解約ができるというわけ。この点が、今、外貨取引をするなら、外貨普通預金がオススメの最大の理由です。
昼間は忙しいので市場の動きに張り付いて、注文をしている時間がないという人も実は大丈夫。外貨普通預金でありながら、為替レートの指値注文ができるのです。もう少し詳しく指値について説明すると、たとえば、現在の為替レートが104円だったとします。もっと円高になるにちがいないと思ったら、為替レートが100円になったら100万円買い付けというように、指値をしておけるわけです。また、逆指値も可能。100円で買い付けをしたが、もし98円になったら売却という指示をしておけば、平日の昼間、市場をみている時間がなくとも、急激な円高を逃げ切ることができるわけです。
このほかにも、同行には複合指値、ウィークエンド指値などのサービスもありますので、詳しく知りたい人は、サイトで確認してください。
また、外貨預金の魅力はいざとなったら、外貨のまま引き出して使える、という点にあります。この点では、住信SBIネット銀行は外貨で引き出すことはできません。ただし、SBIカードという提携カードがあり、このカードで決済するときに「外貨で」と指定すれば、外貨決済の形で外貨をリアルに使うことができます。
どうですか? ネット外貨普通預金。意外に使えませんか?
住信SBIネット銀行以外にも、たとえばソニー銀行の外貨普通預金も優秀です。為替レートは10銭動くたびに見直されますし、為替手数料も住信 SBI銀行とほぼ同じレート。指値注文をすることもできます。また、同行の場合、外貨普通預金から外貨のまま外貨MMFへの資金移動が可能。また、米ドルからなら、1度円に戻すことなく、他の外貨との外貨間取引ができます。
さらに、世界中にある提携ATMから現地通貨で引き出すことができる「MONEY Kitグローバル」サービスもありますので、本当に急激な円高に見舞われてしまったら、塩漬けにせず、外貨として使ってしまうことも可能です。また、イーバンク銀行は、高金利で人気の南アフリカランドを取り扱っています。
あまり知られていないネット銀行の外貨普通預金。この機会に試してみてはどうでしょう。

[science][physics]ダークエネルギー
ダークエネルギー
概要
ダークエネルギーとは、宇宙全体に広がって負の圧力を持ち、実質的に「反発する重力」としての効果を及ぼしている仮想的なエネルギーである。宇宙論研究者のマイケル・ターナーが最初に作った言葉であるとされる。現在観測されている宇宙の加速膨張や、宇宙の大半の質量が正体不明であるという観測事実を説明するために、宇宙論の標準的な理論(ロバートソン-ウォーカー計量)にダークエネルギーを加えるのが現在最もポピュラーな手法である。この新しい宇宙論の標準モデルをΛ-CDMモデルと呼ぶ。現在提案されている2つのダークエネルギーの形態としては、宇宙定数とクインテセンス (quintessence) がある。前者は静的であり後者は動的である。この二つを区別するためには、宇宙膨張を高い精度で測定し、膨張速度が時間とともにどのように変化しているかを調べる必要がある。このような高精度の観測を行うことは観測的宇宙論の主要な研究課題の一つである。
[編集] ダークエネルギーの提唱
宇宙定数はアルベルト・アインシュタインによって、静的な宇宙を表すような場の方程式の定常解を得るための方法として最初に提案された(つまり、実質的にダークエネルギーを重力と釣り合わせるために用いた)。しかし後に、アインシュタインの静的宇宙は、局所的な非一様性が存在すると最後には宇宙スケールで膨張または収縮が暴走的に起こるため、実際には不安定であることが明らかになった。また、より重要な点として、エドウィン・ハッブルの観測によって、宇宙は膨張しており、静的ではありえないことが明らかになった。この発見の後、宇宙定数は歴史上の奇妙な存在としてほぼ無視されることとなった。
1970年代にはアラン・グースが、ごく初期の宇宙で宇宙定数が宇宙のインフレーションを起こした可能性を提案した。しかしインフレーションモデルが広く受け入れられた後でも、宇宙定数はごく初期の宇宙においてのみ重要であり、現在の宇宙とは無関係であると信じられていた。しかし、1990年代の終わりに人工衛星と望遠鏡の黄金時代を迎えると、遠方の超新星や宇宙背景放射を高い精度で測定することが可能になった。これらの観測で驚くべき結果が得られたが、これらの結果のうちのいくつかは、何らかの形でダークエネルギーが現在の宇宙に存在すると仮定すると最も簡単に説明できるものだった。
[編集] 現象論的性質
ダークエネルギーには互いに反発する性質があるため、宇宙膨張を加速する原因となりうる。これは物質優勢の宇宙という伝統的な描像で膨張の減速が起こると予想されているのとは対照的である。宇宙の加速膨張は多くの遠方の超新星の観測から示唆されている。
宇宙の全エネルギー密度の研究からも別の議論がもたらされている。理論的・観測的研究から、宇宙の全エネルギー密度は宇宙がちょうど平坦になる(すなわち、一般相対性理論で定義される時空の曲率が大きなスケールで 0 になる)ような臨界密度に非常に近いことが昔から知られている。(特殊相対性理論の E = mc2 から)エネルギーは質量と等価なので、これは通常、宇宙が平坦になるのに必要な臨界質量密度と呼ばれる。光を放出する通常の物質の観測からは、必要な質量密度の2-5%しか説明できない。この足りない質量を補うために、ダークマターと呼ばれる目に見える光を放出しない物質の存在が長い間仮定されてきた。しかし、1990年代に行われた銀河や銀河団の観測で、ダークマターをもってしても臨界質量密度の25%しか説明できないことが強く示唆された。もしダークエネルギーが臨界エネルギー密度の残りの約70%を補えば、全エネルギー密度は宇宙が平坦であるのに必要な量と矛盾しなくなる。
[編集] 推測
このダークエネルギーの真の正体は現状ではほぼ推測の対象にすぎない。ダークエネルギーは一般相対論の宇宙定数(Λ)で表される真空のエネルギーではないか、と考える人々も多く、実際、これはダークエネルギーに対する最も単純な説明である。宇宙定数は、時間や宇宙膨張によらず宇宙全体に存在する一様密度のダークエネルギーと解釈できるからである。これはアインシュタインによって導入された形式のダークエネルギーであり、我々の現在までの観測と矛盾しない。ダークエネルギーがこのような形をとるとすると、これはダークエネルギーが宇宙の持つ基本的な特徴であることを示すことになる。これとは別に、ダークエネルギーはある種の動力学的な場が粒子的に励起したものとして生まれるとする考え方もあり、クインテセンスと呼ばれている。クインテセンスは空間と時間に応じて変化する点で宇宙定数とは異なっている。クインテセンスは物質のように互いに集まって構造を作るといったことがないように、非常に軽くなければならない(大きなコンプトン波長を持つ)。今のところクインテセンスが存在する証拠は得られていないが、存在の否定もされていない。
[編集] インフレーション
ダークエネルギーはインフレーション宇宙論と密接に関係しているという点は注意が必要である。インフレーションはダークエネルギーと定性的に同様の、何らかの反発力の存在を前提としている。これによって宇宙はビッグバンの直後に急速な指数関数的膨張を引き起こす。このような膨張はほとんどの現在の宇宙論や構造形成論の本質的な特徴である。しかし、インフレーションは現在我々が観測しているダークエネルギーよりももっとずっと高いエネルギー密度で起きなければならないし、宇宙の一生の初期で完全に終わっているはずだと考えられている。したがって、ダークエネルギーとインフレーションの間にもし関係があるとしても、それがどのようなものなのかについては分かっていない。
[編集] ダークエネルギーが示唆する未来
もしも仮想的なダークエネルギーが宇宙のエネルギーバランスにおいて支配的であり続けるなら、現在の宇宙膨張は加速し続け、ついにはド・ジッター宇宙として知られる文字通り指数関数的な膨張となる。
このモデルでは、重力的に束縛されていない構造は見かけ上、光速を超える速度でばらばらに飛び去ることになる。宇宙に関する我々の知識は光速より遅く伝わる信号によってしか得られないため、この加速によって最終的には、現在見えている遠方の宇宙を見ることすらできなくなる。しかし、ダークエネルギーの密度が増えなければ、銀河や太陽系など現在重力的に束縛されているどんな構造もそのまま残る。したがって我々の地球や銀河系は、宇宙の他の存在が全て我々から離れ去ってもほぼそのまま乱されることなく存在し続ける。
あるいは、ダークエネルギーは一定ではなく、時間とともに増えているかもしれない。「幽霊エネルギー (en:phantom energy)」と呼ばれるこのシナリオでは、宇宙に存在する全てのものは原子に分解され、最後にはビッグリップによって吹き飛ばされてしまい、構造のない空っぽの宇宙が残される。
また、最終的にはダークエネルギーは時間とともに散逸し、宇宙は互いに引き合うようになるかもしれない。このような不確定性があるために、やはり重力が宇宙を支配し、やがては宇宙が自ら潰れるビッグクランチに至るという可能性も残されている。しかしこれは一般的には最も可能性の低いシナリオだと考えられている。
2008年10月28日火曜日
Dark energy - Wikipedia, the free encyclopedia
Dark energy - Wikipedia, the free encyclopedia
In physical cosmology, dark energy is a hypothetical exotic form of energy that permeates all of space and tends to increase the rate of expansion of the universe.[1] Dark energy is the most popular way to explain recent observations that the universe appears to be expanding at an accelerating rate. In the standard model of cosmology, dark energy currently accounts for 74% of the total mass-energy of the universe.Two proposed forms for dark energy are the cosmological constant, a constant energy density filling space homogeneously,[2] and scalar fields such as quintessence or moduli, dynamic quantities whose energy density can vary in time and space. Contributions from scalar fields that are constant in space are usually also included in the cosmological constant. The cosmological constant is physically equivalent to vacuum energy. Scalar fields which do change in space can be difficult to distinguish from a cosmological constant because the change may be extremely slow.
High-precision measurements of the expansion of the universe are required to understand how the expansion rate changes over time. In general relativity, the evolution of the expansion rate is parameterized by the cosmological equation of state. Measuring the equation of state of dark energy is one of the biggest efforts in observational cosmology today.
Adding the cosmological constant to cosmology's standard FLRW metric leads to the Lambda-CDM model, which has been referred to as the "standard model" of cosmology because of its precise agreement with observations. Dark energy has been used as a crucial ingredient in a recent attempt[3] to formulate a cyclic model for the universe.
Contents
[hide]Evidence for dark energy
Supernovae
In 1998, observations of type 1a supernovae ("one-A") by the Supernova Cosmology Project at the Lawrence Berkeley National Laboratory and the High-z Supernova Search Team suggested that the expansion of the universe is accelerating.[4][5] Since then, these observations have been corroborated by several independent sources. Measurements of the cosmic microwave background, gravitational lensing, and the large scale structure of the cosmos as well as improved measurements of supernovae have been consistent with the Lambda-CDM model.[6]
Supernovae are useful for cosmology because they are excellent standard candles across cosmological distances. They allow the expansion history of the Universe to be measured by looking at the relationship between the distance to an object and its redshift, which gives how fast it is receding from us. The relationship is roughly linear, according to Hubble's law. It is relatively easy to measure redshift, but finding the distance to an object is more difficult. Usually, astronomers use standard candles: objects for which the intrinsic brightness, the absolute magnitude, is known. This allows the object's distance to be measured from its actually observed brightness, or apparent magnitude. Type Ia supernovae are the best-known standard candles across cosmological distances because of their extreme, and extremely consistent, brightness.
Cosmic Microwave Background
 Estimated distribution of dark matter and dark energy in the universe
Estimated distribution of dark matter and dark energy in the universeThe existence of dark energy, in whatever form, is needed to reconcile the measured geometry of space with the total amount of matter in the universe. Measurements of cosmic microwave background (CMB) anisotropies, most recently by the WMAP satellite, indicate that the universe is very close to flat. For the shape of the universe to be flat, the mass/energy density of the universe must be equal to a certain critical density. The total amount of matter in the universe (including baryons and dark matter), as measured by the CMB, accounts for only about 30% of the critical density. This implies the existence of an additional form of energy to account for the remaining 70%.[6] The most recent WMAP observations are consistent with a universe made up of 74% dark energy, 22% dark matter, and 4% ordinary matter. (Note: There is a slight discrepancy in the 'pie chart'.)
Large-Scale Structure
The theory of large scale structure, which governs the formation of structure in the universe (stars, quasars, galaxies and galaxy clusters), also suggests that the density of matter in the universe is only 30% of the critical density.
Late-time Integrated Sachs-Wolfe Effect
Accelerated cosmic expansion causes gravitational potential wells and hills to flatten as photons pass through them, producing cold spots and hot spots on the CMB aligned with vast supervoids and superclusters. This so-called late-time Integrated Sachs-Wolfe effect (ISW) is a direct signal of dark energy in a flat universe,[7] and has recently been detected at high significance by Ho et al.[8] and Giannantonio et al.[9] In May 2008, Granett, Neyrinck & Szapudi found arguably the clearest evidence yet for the ISW effect,[10] imaging the average imprint of superclusters and supervoids on the CMB.
Nature of dark energy
The exact nature of this dark energy is a matter of speculation. It is known to be very homogeneous, not very dense and is not known to interact through any of the fundamental forces other than gravity. Since it is not very dense?roughly 10?29 grams per cubic centimeter?it is hard to imagine experiments to detect it in the laboratory. Dark energy can only have such a profound impact on the universe, making up 74% of all energy, because it uniformly fills otherwise empty space. The two leading models are quintessence and the cosmological constant. Both models include the common characteristic that dark energy must have negative pressure.
Negative Pressure
Independently from its actual nature, dark energy would need to have a strong negative pressure in order to explain the observed acceleration in the expansion rate of the universe.
According to General Relativity, the pressure within a substance contributes to its gravitational attraction for other things just as its mass density does. This happens because the physical quantity that causes matter to generate gravitational effects is the Stress-energy tensor, which contains both the energy (or matter) density of a substance and its pressure and viscosity.
In the Friedmann-Lemaitre-Robertson-Walker metric, it can be shown that a strong constant negative pressure in all the universe causes an acceleration in universe expansion if the universe is already expanding, or a deceleration in universe contraction if the universe is already contracting. More exactly, the second derivative of the universe scale factor,
, is positive if the equation of state of the universe is such that w < ? 1 / 3.
This accelerating expansion effect is sometimes labeled "gravitational repulsion", which is a colorful but possibly confusing expression. In fact a negative pressure does not influence the gravitational interaction between masses - which remains attractive - but rather alters the overall evolution of the universe at the cosmological scale, typically resulting in the accelerating expansion of the universe despite the attraction among the masses present in the universe.
Cosmological constant
The simplest explanation for dark energy is that it is simply the "cost of having space": that is, a volume of space has some intrinsic, fundamental energy. This is the cosmological constant, sometimes called Lambda (hence Lambda-CDM model) after the Greek letter Λ, the symbol used to mathematically represent this quantity. Since energy and mass are related by E = mc2, Einstein's theory of general relativity predicts that it will have a gravitational effect. It is sometimes called a vacuum energy because it is the energy density of empty vacuum. In fact, most theories of particle physics predict vacuum fluctuations that would give the vacuum exactly this sort of energy. This is related to the Casimir Effect, in which there is a small suction into regions where virtual particles are geometrically inhibited from forming (e.g. between plates with tiny separation). The cosmological constant is estimated by cosmologists to be on the order of 10?29g/cm3, or about 10?120 in reduced Planck units. Particle physics predicts a natural value of 1 in reduced Planck units, quite a bit off.
The cosmological constant has negative pressure equal to its energy density and so causes the expansion of the universe to accelerate. The reason why a cosmological constant has negative pressure can be seen from classical thermodynamics; Energy must be lost from inside a container to do work on the container. A change in volume dV requires work done equal to a change of energy ?p dV, where p is the pressure. But the amount of energy in a box of vacuum energy actually increases when the volume increases (dV is positive), because the energy is equal to ρV, where ρ (rho) is the energy density of the cosmological constant. Therefore, p is negative and, in fact, p = ?ρ.
A major outstanding problem is that most quantum field theories predict a huge cosmological constant from the energy of the quantum vacuum, more than 100 orders of magnitude too large.[11] This would need to be cancelled almost, but not exactly, by an equally large term of the opposite sign. Some supersymmetric theories require a cosmological constant that is exactly zero, which does not help. The present scientific consensus amounts to extrapolating the empirical evidence where it is relevant to predictions, and fine-tuning theories until a more elegant solution is found. Philosophically, our most elegant solution may be to say that if things were different, we would not be here to observe anything ? the anthropic principle.[12] Technically, this amounts to checking theories against macroscopic observations. Unfortunately, as the known error-margin in the constant predicts the fate of the universe more than its present state, many such "deeper" questions remain unknown.
Another problem arises with inclusion of the cosmic constant in the standard model: i.e., the appearance of solutions with regions of discontinuities (see classification of discontinuities for three examples) at low matter density.[13] Discontinuity also affects the past sign of the pressure assigned to the cosmic constant, changing from the current negative pressure to attractive, as one looks back towards the early Universe. A systematic, model-independent evaluation of the supernovae data supporting inclusion of the cosmic constant in the standard model indicates these data suffer systematic error. The supernovae data are not overwhelming evidence for an accelerating Universe expansion which may be simply gliding.[14] A numerical evaluation of WMAP and supernovae data for evidence that our local group exists in a local void with poor matter density compared to other locations, uncovered possible conflict in the analysis used to support the cosmic constant.[15] These findings should be considered shortcomings of the standard model, but only when a term for vacuum energy is included.
In spite of its problems, the cosmological constant is in many respects the most economical solution to the problem of cosmic acceleration. One number successfully explains a multitude of observations. Thus, the current standard model of cosmology, the Lambda-CDM model, includes the cosmological constant as an essential feature.
Quintessence
In quintessence models of dark energy, the observed acceleration of the scale factor is caused by the potential energy of a dynamical field, referred to as quintessence field. Quintessence differs from the cosmological constant in that it can vary in space and time. In order for it not to clump and form structure like matter, the field must be very light so that it has a large Compton wavelength.
No evidence of quintessence is yet available, but it has not been ruled out either. It generally predicts a slightly slower acceleration of the expansion of the universe than the cosmological constant. Some scientists think that the best evidence for quintessence would come from violations of Einstein's equivalence principle and variation of the fundamental constants in space or time. Scalar fields are predicted by the standard model and string theory, but an analogous problem to the cosmological constant problem (or the problem of constructing models of cosmic inflation) occurs: renormalization theory predicts that scalar fields should acquire large masses.
The cosmic coincidence problem asks why the cosmic acceleration began when it did. If cosmic acceleration began earlier in the universe, structures such as galaxies would never have had time to form and life, at least as we know it, would never have had a chance to exist. Proponents of the anthropic principle view this as support for their arguments. However, many models of quintessence have a so-called tracker behavior, which solves this problem. In these models, the quintessence field has a density which closely tracks (but is less than) the radiation density until matter-radiation equality, which triggers quintessence to start behaving as dark energy, eventually dominating the universe. This naturally sets the low energy scale of the dark energy.
Some special cases of quintessence are phantom energy, in which the energy density of quintessence actually increases with time, and k-essence (short for kinetic quintessence) which has a non-standard form of kinetic energy. They can have unusual properties: phantom energy, for example, can cause a Big Rip.
Alternative ideas
Some theorists think that dark energy and cosmic acceleration are a failure of general relativity on very large scales, larger than superclusters. It is a tremendous extrapolation to think that our law of gravity, which works so well in the solar system, should work without correction on the scale of the universe. Most attempts at modifying general relativity, however, have turned out to be either equivalent to theories of quintessence, or inconsistent with observations. It is of interest to note that if the equation for gravity were to approach r instead of r2 at large, intergalactic distances, then the acceleration of the expansion of the universe becomes a mathematical artifact,[clarify] negating the need for the existence of Dark Energy.
Alternative ideas for dark energy have come from string theory, brane cosmology and the holographic principle, but have not yet proved as compelling as quintessence and the cosmological constant. On string theory, an article in the journal Nature described:
String theories, popular with many particle physicists, make it possible, even desirable, to think that the observable universe is just one of 10500 universes in a grander multiverse, says [Leonard Susskind, a cosmologist at Stanford University in California]. The vacuum energy will have different values in different universes, and in many or most it might indeed be vast. But it must be small in ours because it is only in such a universe that observers such as ourselves can evolve.[11]
Paul Steinhardt in the same article criticizes string theory's explanation of dark energy stating "...Anthropics and randomness don't explain anything... I am disappointed with what most theorists are willing to accept".[11]
In a rather radical departure, an article in the open access journal, Entropy, by Professor Paul Gough, put forward the suggestion that information energy must make a significant contribution to dark energy and that this can be shown by referencing the equation of the state of information in the universe. [16]
Yet another, "radically conservative" class of proposals aims to explain the observational data by a more refined use of established theories rather than through the introduction of dark energy, focusing, for example, on the gravitational effects of density inhomogeneities [17][18] or on consequences of electroweak symmetry breaking in the early universe.
Implications for the fate of the universe
Cosmologists estimate that the acceleration began roughly 5 billion years ago. Before that, it is thought that the expansion was decelerating, due to the attractive influence of dark matter and baryons. The density of dark matter in an expanding universe decreases more quickly than dark energy, and eventually the dark energy dominates. Specifically, when the volume of the universe doubles, the density of dark matter is halved but the density of dark energy is nearly unchanged (it is exactly constant in the case of a cosmological constant).
If the acceleration continues indefinitely, the ultimate result will be that galaxies outside the local supercluster will move beyond the cosmic horizon: they will no longer be visible, because their line-of-sight velocity becomes greater than the speed of light. This is not a violation of special relativity, and the effect cannot be used to send a signal between them. (Actually there is no way to even define "relative speed" in a curved spacetime. Relative speed and velocity can only be meaningfully defined in flat spacetime or in sufficiently small (infinitesimal) regions of curved spacetime). Rather, it prevents any communication between them and the objects pass out of contact. The Earth, the Milky Way and the Virgo supercluster, however, would remain virtually undisturbed while the rest of the universe recedes. In this scenario, the local supercluster would ultimately suffer heat death, just as was thought for the flat, matter-dominated universe, before measurements of cosmic acceleration.
There are some very speculative ideas about the future of the universe. One suggests that phantom energy causes divergent expansion, which would imply that the effective force of dark energy continues growing until it dominates all other forces in the universe. Under this scenario, dark energy would ultimately tear apart all gravitationally bound structures, including galaxies and solar systems, and eventually overcome the electrical and nuclear forces to tear apart atoms themselves, ending the universe in a "Big Rip". On the other hand, dark energy might dissipate with time, or even become attractive. Such uncertainties leave open the possibility that gravity might yet rule the day and lead to a universe that contracts in on itself in a "Big Crunch". Some scenarios, such as the cyclic model suggest this could be the case. While these ideas are not supported by observations, they are not ruled out. Measurements of acceleration are crucial to determining the ultimate fate of the universe in big bang theory.
History
The cosmological constant was first proposed by Einstein as a mechanism to obtain a stable solution of the gravitational field equation that would lead to a static universe, effectively using dark energy to balance gravity. Not only was the mechanism an inelegant example of fine-tuning, it was soon realized that Einstein's static universe would actually be unstable because local inhomogeneities would ultimately lead to either the runaway expansion or contraction of the universe. The equilibrium is unstable: if the universe expands slightly, then the expansion releases vacuum energy, which causes yet more expansion. Likewise, a universe which contracts slightly will continue contracting. These sorts of disturbances are inevitable, due to the uneven distribution of matter throughout the universe. More importantly, observations made by Edwin Hubble showed that the universe appears to be expanding and not static at all. Einstein famously referred to his failure to predict the idea of a dynamic universe, in contrast to a static universe, as his greatest blunder. Following this realization, the cosmological constant was largely ignored as a historical curiosity.
Alan Guth proposed in the 1970s that a negative pressure field, similar in concept to dark energy, could drive cosmic inflation in the very early universe. Inflation postulates that some repulsive force, qualitatively similar to dark energy, resulted in an enormous and exponential expansion of the universe slightly after the Big Bang. Such expansion is an essential feature of most current models of the Big Bang. However, inflation must have occurred at a much higher energy density than the dark energy we observe today and is thought to have completely ended when the universe was just a fraction of a second old. It is unclear what relation, if any, exists between dark energy and inflation. Even after inflationary models became accepted, the cosmological constant was thought to be irrelevant to the current universe.
The term "dark energy" was coined by Michael Turner in 1998.[19] By that time, the missing mass problem of big bang nucleosynthesis and large scale structure was established, and some cosmologists had started to theorize that there was an additional component to our universe. The first direct evidence for dark energy came from supernova observations of accelerated expansion, in Riess et al[5] and later confirmed in Perlmutter et al..[4] This resulted in the Lambda-CDM model, which as of 2006 is consistent with a series of increasingly rigorous cosmological observations, the latest being the 2005 Supernova Legacy Survey. First results from the SNLS reveal that the average behavior (i.e., equation of state) of dark energy behaves like Einstein's cosmological constant to a precision of 10 per cent.[20] Recent results from the Hubble Space Telescope Higher-Z Team indicate that dark energy has been present for at least 9 billion years and during the period preceding cosmic acceleration.

2008年10月27日月曜日
[dev][sbm]Kikker の学習の仕組みと Rocchio アルゴリズム - naoyaのはてなダイアリー
Kikker の学習の仕組みと Rocchio アルゴリズム - naoyaのはてなダイアリー
Kikker の学習の仕組みと Rocchio アルゴリズム
先日のソーシャルブックマーク研究会では id:kanbayashi さんによる発表がありました。id:kanbayashi さんは Kikker や はてブまわりのひと などの開発をされている方です。最近情報検索理論に入門した自分にとっては、非常に面白い発表でした。
発表の中で Kikker の学習の仕組みについての解説もありました。Kikker は Cosine similarity で推薦するドキュメントを検索しているそうですが、ユーザーのクリックデータを使って、ユーザーごとに推薦対象を最適化するようにしているそうです。この学習は、ユーザーが見たページのベクトルを、そのユーザーの趣向ベクトルに足し込むことで実現している、とのことでした。
発表ではベクトルを加算することについて「たぶんこれでうまくいく」とのことでしたが、先日 IIR の9章の復習をしていて、これは Rocchio アルゴリズムそのものなのだな、ということに気づきました。
Rocchio アルゴリズムは、検索結果の適合度を改善するための適合性フィードバック (Relevance feedback) を実現する古典的なアルゴリズムです。ユーザーからポジティブもしくはネガティブなフィードバックを受け取って、そのフィードバックから検索クエリを改善します。
例えばユーザーが、ある検索クエリ q に対する検索結果ドキュメント群のうちドキュメント d1 とドキュメント d3 は relevant であると判断したら、それをシステムに入力させます。d1, d3 は、relevant なドキュメントの集合全体 Cr から見ると、部分集合になっています。これを Dr とします。ベクトル空間上では位置ベクトルで Dr の重心ベクトルが求められます。検索クエリのベクトル q を Dr の重心に近づけると、(Dr の周辺は relevant なドキュメントが固まっているという前提が成立するなら) より relevant な集合に類似したベクトルへと最適化されます。
上記が Rocchio アルゴリズムの式です。qm が最適化されたベクトル、q0 が最初のクエリ、右辺の二項目が relevant なドキュメント部分集合 Dr の重心ベクトル、三項目が non-relevant な集合 Dnr の重心ベクトルです。重心ベクトルを加算することでクエリの位置ベクトルは relevant なクラスタへ近づき、
除算減算することで non-relevant なクラスタから遠ざかります。α、β、γ は重み付けの係数です。フィードバックとして返却されるドキュメントが多いならβ、γの値を大きくするとより強くフィードバックがかかります。
Kikker ではクリックがあったドキュメントを relevant だと学習するようです。これはポジティブフィードバックのみで、ネガティブフィードバックがないことを意味します。従ってこの場合 γ = 0 の場合に等しく、Dnr の重心ベクトルは利用していないことになります。IIR#9 ではポジティブフィードバックはネガティブフィードバックより役に立つので重みを強く付けるよう推薦されていますし、ネガティブフィードバックを必要としないシステムは γ = 0 であると解説があります。
クリックがあったドキュメントのベクトルを趣向ベクトル (クエリベクトル) に足し込んでるとのことなので、これは Rocchio アルゴリズムでクエリベクトルを重心に近づけていることにほぼ等しいのだと思いました。(足し込んだベクトル数で正規化すると、より精度が上がる、ということになるでしょうか。) ベクトルの加算で学習がうまくいっているのにはこのような裏付けがあると言えそうです。
[dev]blogeyeの実装に学ぶ、Amazon EC2/S3でのHadoop活用術
blogeyeの実装に学ぶ、Amazon EC2/S3でのHadoop活用術:CodeZine
blogeyeとは
「blogeye」(ブログアイ)は日本語のブログをクロール、リアルタイムに分析して、流行語と思われるものを推定し、ランキング形式で提供しているサイトです。特徴として、ブログサイトごとにその著者の性別・年齢・居住都道府県を推定しているため、流行語を著者属性ごとに推定したり、ユーザーが入力したキーワードや流行語を特によく使っている著者属性を表示したりすることができます。
blogeye
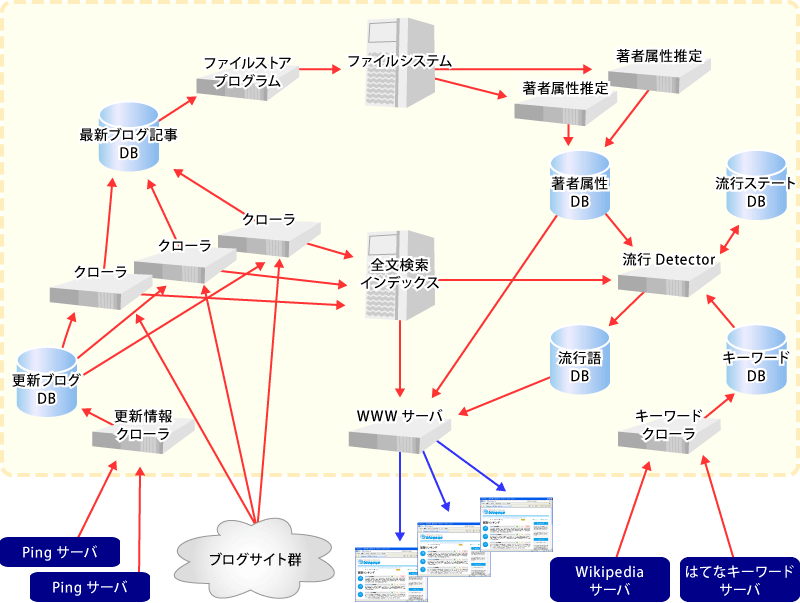
blogeyeの構成
blogeye全体の構成は下図のようになっています。
ブログのクローリング
まず、更新情報のクローラ(図の左下)がPingサーバーからブログの更新情報を取得し、更新ブログデータベース(MySQL)に格納しています。この更新ブログデータベースの情報を元に、クローラがブログサイトにアクセスし、記事を取得します。このクローリング処理はHadoopで分散処理されます。
ブログ記事データベースにまだ含まれていない記事であればそれをブログ記事データベース(MySQL)に挿入すると共に、一時的な全文検索インデックス(Senna)に登録します。ブログ記事データベースのデータは1日に1回、ファイルシステム(S3)に書き込み、記事データベースからは削除します。
著者属性の推定
著者属性推定プログラム(図の右上)は、ファイルシステム(S3)から過去にクロールしたすべての記事データを読み出し、日付ごとに管理されている記事をブログサイトごとにまとめなおして、各々のサイトについて著者属性を推定し、結果を著者属性データベースに格納します。
流行度スコアの算出
キーワードクローラ(図の右下)はWikipediaの更新情報などからキーワードリストを取得し、キーワードデータベースに登録します。キーワードデータベースに登録されたデータは全文検索インデックスと著者属性データベースと共に流行Detector(流行度スコア計算のプログラム)で処理され、結果の流行度スコアが流行語データベースに登録されます。
流行語のランキングを表示
ユーザー(図の中央下部)がブラウザを通じてクエリを送ると、Webサーバが流行語データベースや全文検索インデックスの内容を参照してページを生成し、ブラウザに返送します。
Amazon EC2/S3の利用
blogeyeでは1日に50万~70万のブログ記事をクロールしており、システム内部には2億ページ強の記事を保管しています。blogeyeで行っている並列化が必要な処理は、大きく分けて2つあります。
1つはブログの更新情報を提供しているサービスであるpingサーバからのデータ取得や、ブログ記事の取得などの「クロール処理」です。2つ目は、「著者属性を推定する処理」です。クロールのように常に行う処理ではないですが、クロールしたすべての記事をサイトごとにまとめ直し、各サイトの著者属性を推定する大きな処理です。この2つの処理を行うため、Amazon EC2上に
Hadoopクラスタを構成しました。HadoopとAmazon EC2
HadoopとEC2はとても相性がよく、EC2の特徴である「必要なときに必要なだけ計算機リソースをレンタルできる」という性質を
Hadoopクラスタにも継承できます。
Hadoopクラスタを拡大したい時にはHadoopの開発者コミュニティが用意してくれているAMI(Amazon Machine Image)を自分で起動します。スレーブとして動作させるためのパラメータやマスターのアドレスを与えてこのAMIから起動すれば自動的にマスターに接続し、クラスタのスレーブとして認識されます。逆にクラスタを縮小したい場合には、いくつかのスレーブのインスタンスを単に終了します。終了させたマシンで実行されていたタスクは失敗しますが、Hadoopのマスターはこの失敗を検出して同じタスクを他のマシンに割り当て直すことにより、ジョブを問題なく継続してくれます。HadoopとAmazon S3
また、EC2と共に利用できるS3もHadoopから利用するためのライブラリが提供されており、Hadoopから利用するファイルシステム(HDFS)をS3上に構築することができます。これを利用することで、クラスタ全体を再起動するような際にも、データを失う心配がなくなります。blogeyeでは、ブログデータやHadoopから読み出すデータの多くを HDFSのラッパを通してS3上に保管しています。

Python 3.0 Interview
Python 3.0 Interview
Linux.com :: Python 3.0 makes a big break
I was interviewed for the following article on Python 3.0:
http://www.linux.com/feature/150399While I have no complaints about the way I was quoted, I would have preferred more of the interview to be included, so I'm posting the interview here:
On Sat, Oct 04, 2008, joabjack@comcast.net wrote:
>
> Terrific! Thanks for participating. I'll be sure to put a link in the
> story to your book.
That would be great! Please use http://www.pythonfood.com/
> Could you say approximately how much Python 2.3 or 2.4 code you have
> in your current job? What is this code used for, broadly speaking?
The company I work for is http://www.pagedna.com/ -- it has been in
business for more than ten years and was started with Python 1.4. I've
been working there for more than four years. Our software is a web
application for taking orders and sending EPS/PDF files to printing
plants.
There's more than 200K lines of code, most of it Python. A lot of the
code resides in template files for generating web pages. (There's a
significant amount of JavaScript, much of which is generated by Python
code.) Although EPS/PDF generation is the heart of our application,
there are many ancillary features to meet our customer needs (such as
approval workflow, inventory management, and reporting).
> What are your thoughts about eventually moving that code to 3.0? Would
> this be a big job? At what point, if ever, would it be necessary?
It would be a huge job, made more difficult because many of our bits of
Python code reside in web templates. However, by the time we do the
conversion the tools for automatic conversion should be much improved.
Although both my boss (Tony Lownds) and I are active in the Python
community, we haven't even talked about 3.0 -- it's at least two or
three years away.
> In your opinion, do you think it's a wise move to forgo backward
> compatibility in Python 3.0, given both the user base and current
> limitations of the language?
First of all, I think it overstates the case to talk about "forgoing
compatibility". The base Python language is still the same; the only
difference immediately apparent at the simple scripting level is that the
print command has changed to a function. Python 3.0 is more about
removing mistakes and warts, many of which people have been encouraged to
avoid for years.
In addition, it is the intention to gradually merge the 2.x and 3.x
series; Python 2.6 is already a major step in that direction.
All in all, I think Python 3.0 is the kind of necessary evolution that
software needs. It certainly isn't as big a change as going from DOS to
Windows or from Mac OS 9 to OS X.
> What qualities about Python first attracted you to the language?
Actually, I was forced to learn Python. I was a Perl expert at the time,
and I saw no reason to learn yet another scripting language. Since then,
I have become enamored of Python's readability and how a typical
programmer's pseudocode is trivially translated into running Python.
> Of what you read about Python 3.0, what features do you find most
> intriguing?
The fact that it's getting done at all! For years, Python 3.0 was
referred to as Python 3000 -- the joke being that it would happen in the
year 3000 (meaning, never). Work only started seriously three years ago,
and I think that Python 3.0 has done an excellent job of balancing the
past and the future.
> That's about it, though if you have any other thoughts about Python
> 3.0, I'd love to hear them as well.
That pretty much covers it, I think.
Linux.com :: Python 3.0 makes a big break
Typically, each new version of the Python programming language has been gentle on users, more or less maintaining backward compatibility with previous versions. But in 2000, when Python creator Guido van Rossum announced that he was embarking on a new version of Python, he did not sugar coat his plan: Version 3.0 would not be backward-compatible. Now that the first release candidate of Python 3.0 is out, with final release planned for later this month, developers must grapple with the issue of whether to maintain older code or modify it to use the new interpreter.
Developers hate it when a new version of a language doesn't work with the code written for older versions of that language, but for van Rossum, the radical upgrade was necessary. The language was becoming ever more weighed down by multiple ways of doing the same task, and ways of doing tasks no one ever actually did.
"The motivation for 3.0 was to have one specific event where we did as much of the backward incompatibility all at once," van Rossum says. The idea is to "give the language a better foundation for going forward."
Naturally, some stirrings of discontent can be felt across the Python community.
"Python is pretty much determined to remove itself from consideration from various kinds of international projects like the one I work on. We're already catching flak from people due to a few things that were valid in 2.2 that are not valid in 2.3," bemoaned one developer in the comp.lang.python newsgroup.
"For an operating system distributor, Python 3.0 represents a large potential change in their repository of packages for relatively little benefit in terms of resulting functionality," says UK Python developer Paul Boddie.
What changes?
In a way, Python has been a victim of its own success. "The original idea for the language had a much smaller scope. I really hadn't expected it to be so successful and being used in a wide variety of applications, from Web applications to scientific calculations, and everything in between," van Rossum says.
Van Rossum first created Python in 1990, as an open source, extensible, high-level language that he needed to handle some system administration duties. Today, Python is one of the most popular languages used world-wide. In March 2008, Austrian researcher Anton Ertl ranked programming languages in terms of their popularity as gauged by the number of postings in Usenet newsgroups. Python proved to be the third most-discussed language on Usenet, right after C and Java, ahead of such stalwarts as C++ and Perl.
When it comes time to teach someone how to program, often the easiest programming language to use is Python. It is the Basic of today, though more elegant to work with than Basic ever was.
Yet Python's simplicity was being threatened by the unchecked growth of the language, van Rossum says. Throughout the '90s, new functions and features were bolted onto the language, and inconsistencies started popping up across the platform. "We were slowly losing the advantage" of simplicity. "We had to break backward compatibility. The alternative was unchecked bloat of the language definition, which happens very slowly and almost unnoticeable."
Python.org has a list of changes to the language. Some are small, and will go unnoticed by most programmers. Others can be relearned quickly.
"Most of the differences are in the details; the general gist of the language, how people think about the language and the capabilities are pretty much unchanged," van Rossum says.
For instance, the print statement got turned into a print function; you must now put parentheses around what you want to print to the screen. The change allows developers to work with print in a more flexible and uniform way. If someone needs to replace the print function with some other action, it can be done with a universal search and replace, rather than rewriting each print statement by hand.
Another change: The language only has one integer type, instead of the former distinction between long and short integers, which van Rossum characterizes as worthless.
Another tangle of cruft that has been pruned back is something called "classic classes." Python version 2 has two sets of classes, each with its own format. "There was a lot of machinery in the Python virtual machine that was either special-casing classic classes or double implementations with version for classic classes and another version for new-style classes. This was implementation bloat," van Rossum says. So, after six years of campaigning to get people to move to the new classes, the developers of Python 3 have put their collective foot down and are doing away with the classic classes.
Perhaps the biggest change that takes place with Python -- and the one that will require the most rewriting of existing code -- is the new way Python deals with bytes and strings. Originally, Python represented all input and output as strings. When Python was used more in casual settings, most strings that went through the interpreter could easily be represented by the standard ASCII character set. But as the language's use grew to global proportions, more and more users started using Unicode to support a wider array of language characters. To Python, Unicode looked a lot like 8-bit binary byte strings, which could be passed along to the interpreter as part of the output from another program. In some cases, the interpreter would confuse binary data with Unicode-encoded strings, and it would choke, big-time.
The answer? Define a new object class for handling bytes -- a first for Python. Also, redefine strings as Unicode. And then keep the two clear of one another. In other words, the byte type and string type are not compatible in Python 3.0.
"If you ever make the mistake of passing bytes around where you think they are text, your code will raise an exception almost immediately," van Rossum said.
Conversion and converts
van Rossum admits now that he didn't think much of the transition difficulties when he first started thinking about Python 3.0. "In 2000, the community was small enough that I thought that I would just release a new version and people would fix their code and that is that."
In the feedback process with the user community though, the core developers started hearing more clamor for a smooth transition process. They needed tools.
This is the role of the recently released version 2.6 of Python, which will serve as a transition version of the language. Users can easily upgrade their code from earlier versions of Python to version 2.6. The 2.6 interpreter will offer warning messages about aspects of the program that will no longer fly with version 3.0.
"We're encouraging people to upgrade to Python 2.6," van Rossum says. "2.6 can help you find the anachronisms in your code that you will need to change to be prepared for 3.0."
The development team also created a transition tool called 2to3 that converts Python 2.6 code into Python 3.0 code. You can then run your older code in 2.6, rewriting it until all the warning messages have been eliminated, then use 2to3 to convert the code into Python 3.0 specs.
Of course, since Python is a dynamic language, where types are not explicitly declared, there are a lot of cases where a translation tool will not help much, but it should help with the mundane tasks, such as changing print statements into print functions.
Even with this tools in place, van Rossum admits that the migration of the user community will be a slow haul, and not all Python shops will make the transition.
For instance, the printing preparation company Aahz Maruch works for, Page DNA, relies on 200,000 lines of Python code in its core revenue-generating operations. "It would be a huge job" to translate this code into Python 3.0, Maruch says. He says the company will wait for a few years for the automatic translation tools to improve. "We haven't even talked about 3.0 -- it's at least two or three years away."
Others are more skeptical about the necessity of the upgrade.
The "implementation of Python 3.0 gives relatively little attention to [current] issues [modern programming languages face], such as performance, pervasive concurrency, or the provision of a renewed, coherent bundled library," Boddie says.
He says there is a danger that Python 3.0 may not be seen as a necessary upgrade for most developers and, as a result, it could lose its status as the de facto Python in much the same way Windows Vista hasn't become the de facto Windows over its predecessor Windows XP.
Today, the chief implementation of Python is CPython, which is a Python interpreter written in C. However, Boddie notes that other implementations exist, such as JPython (Python in Java), IronPython (Python written in Microsoft .Net's Common Runtime Language), and PyPy (a Python interpreter written in Python).
"I think that Python 3.0 may actually focus attention on other Python implementations, particularly if these do not pursue Python 3.0 compatibility as a priority," Boddie suggests.
Nonetheless, the core development team is confident the tide will turn their way, eventually. "I expect that most people will be using 2.6 a year from now. Only bleeding edge people will be using 3.0," van Rossum says. However, "if you're starting a brand new thing, you should use 3.0."
2008年10月24日金曜日
Brian "Krow" Aker's Idle Thoughts - Assumptions, Drizzle
Brian "Krow" Aker's Idle Thoughts - Assumptions, Drizzle
from:
from:
from:
from:
from:
from:
from:
from:
What is the future of Drizzle? What sort of assumptions are you making?
Hardware
On the hardware front I get a lot of distance saying "the future is 64bit, multi-core, and runs on SSD". This is a pretty shallow answer, and is pretty obvious to most everyone. It suits a sound bite but it is not really that revolutionary of a thought. To me the real question is "how do we use them".
64bit means you have to change the way you code. Memory is now flat for the foreseeable future. Never focus on how to map around 32bit issues and always assume you have a large, flat, memory space available. Spend zero time thinking about 32bit.
If you are thinking "multi-core" then think about it massively. Right now adoption is at the 16 core point, which means that if you are developing software today, you need to be thinking about multiples of 16. I keep asking myself "how will this work with 256 cores". Yesterday someone came to me with a solution to a feature we have removed in drizzle. "Look we removed all the locks!". Problem was? The developer had used a compare and swap, CAS, operation to solve the problem. Here is the thing, CAS does not scale with this number of cores/chips that will be in machines. The good thing is the engineer got this, and has a new design :) We won't adopt short term solutions that just kneecap us in the near future.
SSD is here, but it is not here in the sizes needed. What I expect us to do is make use of SSD as a secondary cache, and not look at it as the primary at rest storage. I see a lot of databases sitting in the 20gig to 100gig range. The Library of Congress is 26 terabytes. I expect more scale up so systems will be growing faster in size. SSD is the new hard drive, and fixed disks are tape.
The piece that I have commented least on is the nature of our micro-kernel. We can push pieces of our design out to other nodes. I do not assume Drizzle will live on a single machine. Network speed keeps going up, and we need to be able to tier the database out across multiple computers.
One final thought about Hardware, we need 128bit ints. IPV6, UUID, etc, all of these types mean that we need single instruction operator for 16byte types.Community Development
Today 2/3 of our development comes from outside of the developers Sun pays to work on Drizzle. Even if we add more developers, I expect our total percentage to decrease and not increase. I believe we will see forks and that we have to find ways to help people maintain their forks. One very central piece of what we have to do is move code to the Edge, aka plugins. Thinking about the Edge, has to be a share value.
I see forks as a positive development, they show potential ways we can evolve. Not all evolutionary paths are successful, but it makes us stronger to see where they go. I expect long term for groups to make distributions around Drizzle, I don't know that we will ever do that.
Code drives decisions, and those who provide developers drive those decisions.
While I started out focusing Drizzle on web technologies, we are seeing groups showing up to reuse our kernel in data warehousing and handsets (which is something I never predicted). By keeping the core small we invite groups to use us as a piece to build around.
Drizzle is not all about my vision, it is about where the collective vision takes us.Directions in Database Technology
Map/Reduce will kill every traditional data warehousing vendor in the market. Those who adapt to it as a design/deployment pattern will survive, the rest won't. Database systems that have no concept of being multiple node are pretty much dead. If there is no scale out story, then there is not future going forward.
The way we store data will continue to evolve and diversify. Compression has gotten cheap and processor time has become massive. Column stores will continue to evolve, but they are not a "solves everything" sort of solution. One of the gambles we continue to make is to allow for storage via multiple methods (we refer to this as engines). We will be adding a column store in the near the future, it is an import piece for us to have. Multiple engines cost us in code complexity, but we continue to see value in it. We though will raise the bar on engine design in order to force the complexity of this down to the engine (which will give us online capabilities).
Stored procedures are the dodos for database technology. The languages vendors have designed are limited. On the same token though, putting processing near the data is key to performance for many applications. We need a new model badly, and this model will be a pushdown from two different directions. One direction is obvious, map/reduce, the other direction is the asynchronous queues we see in most web shops. There is little talk about this right now in the blogosphere, but there is a movement toward queueing systems. Queueing systems are a very popular topic in the hallway tracks of conferences.
Databases need to learn how to live in the cloud. We cannot have databases be silos of authentication, processing, and expect only to provide data. We must make our data dictionaries available in the cloud, we need to take our authentication from the cloud, etc...
We need to live in the cloud.Link | Leave a comment
Comments {8}
(no subject)
from: ![[info]](http://p-stat.livejournal.com/img/userinfo.gif) awfief
awfief
date: Oct. 22nd, 2008 06:08 pm (UTC)
Link
the good thing about things like planning for multiple cores, lots of memory, and many different physical machines...
is that it will all work on one behemoth machine if you want it to. Not planning this way right now makes no sense -- obviously we can't predict the future. The most difficult area will likely be disk, since historically that's what's actually changed. RAM hasn't changed (AFAIK), though amounts and speeds have. Disk has changed -- different OS's use different filesystem types, which is essentially different disks, due to usage (and is relevant for issues like fsync). SSD's are one way disks may or may not change in the future....but in the time of records, who envisioned tapes or CD's or mp3 files?
We can try to figure that stuff out....but historically, RAM really hasn't changed, CPU's have changed a bit (layout wise w/multiple cores), and disks have changed the most. This boils down to "make use of everything we know about today, and give the most flexibility to the disk stuff".
perhaps via drizzle plugins? *shrug*
Reply | Thread
(no subject)
from: tanjent
date: Oct. 22nd, 2008 06:12 pm (UTC)
Link
Don't know about Sun's chips, but all modern intel/amd/ppc chips have 128-bit vector registers and a good complement of integer ops (though I don't think any can treat the entire register as one enormous 128-bit int). Windows under x64 actually bypasses the old x87 FPU entirely and does all float math using vector registers - it lets the compiler extract a nice bit of extra parallelism in certain cases.
Reply | Thread
(no subject)
from: krow
date: Oct. 22nd, 2008 06:18 pm (UTC)
Link
I want a single instruction comparison for 128bit ints :)
(Really... a 16byte comparison operation).
I'm not trusting compilers to really optimize for me around this just yet.
Reply | Parent | Thread
(no subject)
from: tanjent
date: Oct. 22nd, 2008 06:32 pm (UTC)
Link
Altivec has vcmp(eq/gt)(s/u)(b/h/w) - vector compare equal/greater signed/unsigned byte/half/word, and docs say it sets the comparison flags appropriately. Don't remember SSE's off the top of my head but they have an equivalent.
Reply | Parent | Thread
(no subject)
from: axehind
date: Oct. 22nd, 2008 06:25 pm (UTC)
Link
Totally agree about moving code to the edge. plugins/modules are the way to go if the interface is easy enough to use. This will spawn lots of sub projects which is a good thing I think!
Not sure I agree with you in regards to SSD. I think using it as a secondary cache could be beneficial right now but I dont see that phase lasting long. I think the jump to all SSD will happen pretty fast.
Reply | Thread
(no subject)
from: mutantgarage
date: Oct. 25th, 2008 04:55 pm (UTC)
Link
NAND Flash SSDs are good for reads, but write performance sucks. They also wear out with a lot of writes, stick a big RAM writeback cache in front of the SSD. This can be hardware or implemented in your application.
Reply | Parent | Thread
Cloud Application Framework
from: oddity80
date: Oct. 22nd, 2008 06:37 pm (UTC)
Link
Very well put (on all topics). In terms or pushing application logic out to where the data lives, we need a dynamic application framework that integrates well into existing web shops while leveraging the power of the cloud. Google and Amazon had the right idea, but they've missed the mark (keep it open, people want more control). There are some solutions that work well for specific purposes (Hadoop), but we still need something more general-purpose. I have a feeling a flexible, open source, language-independent, application framework is right around the corner... or is it already here but just not well known? ;)
Reply | Thread
Agreed on 128 bits.
from: burtonator
date: Oct. 22nd, 2008 07:03 pm (UTC)
Link
I agree on having 128 bits.... I've needed them before.......
Kevin
Reply | Thread
登録:
コメント (Atom)